Anamorphic Property of FT of 2D patterns

Figure 1. Anamorphic property of FT. The left panels refers to the 2D patterns. The right panels refers to the FT of each pattern. a) Tall rectangle apperture produces a wide FT. b) a wide rectangle aperture produces a tall FT. c) Two dots along x-axis symmetric about the center produces an airy pattern with a superimposed sinusoidal signal along y. d) The frequency of the sinusoidal signal decreases when the spacing between the dots is decreased.
Rotation Property of the FT

Figure 2. FT of sines. Left panels refer to the sinusoidal signals. Right panels refer to the FT. a) Sine centered at zero. The FT has two peaks along y centered at zero. b) Sine with a contant bias. FT aside from the two symmetric peaks, also has a peak at zero. c) Sine with a sinusoidal bias. FT has a peak at zero, two small peaks near the origin, and another two far from the origin.

Figure 3. FT of a sinusoid while increasing frequency. Increase in the frequency of the sine shifts the peaks in the FT farther from the origin.

Figure 4. FT of the sinusoid wil a constant bias. A peak at the center can be observed.
A rotated pattern produces an FT rotated in the same direction. This can be observed in figure 5.
Multiplication of patterns produces an FT which is a convolution of the FT of the individual patterns. Figure 6(a) shows the multiplication of a sinusoidal along x and a sinusoidal along y. The FT of a sinusoid along x are two deltas along y, and the FT of a sinusoid along y are two dirac deltas along x. The produces FT in figure 6(a) left panel is a convolution of two dirac deltas along x with two dirac deltas along y. Combining this again with a rotated sinusoid produces an FT with peaks along a rotated axis.

Figure 5. Rotating the sinusoid rotates the FT at the same angle.

Figure 6. Combination of sinusoids. a) Combining a horizontal and a vertical sinusoid (right panel) produces a FT with peaks along X and along Y. b) Combining a rotated sinuoid with the figure in (a) (right panel) produces the same FT but now with peaks along a rotated axis.
Convolution Theorem Redux
In this part the convolution will be more emphasized. The FT of two dirac delta of one pixel as a peak, is a sinusoid. Convolving a dot of some radius with the dirac delta has an Airy pattern with a superimposed sinusoidal FT. For a square convolved with the two dirac deltas, the FT is a sine along x and along y with a superimposed sine signal. For a gaussian convolved with the two dirac deltas, the FT is a gaussian superimposed with a sine signal. This are all shown in figure 7. Increasing the size of the shape convolved with the two dirac deltas, decreases the size of the FT, as can be seen in figures 8-10.

Figure 7. The 2D patterns (left panel) and its FT (left panels). a) binary image of two dots with one pixel each produces a very big FT with a superimposed sine. b) Replacing the dots with circles produces an Airy pattern with a sine of the same frequency. c) Replacing the dots with squares produces a sinusoidal along the center of x and y with a super imposed sine of the same frequency as in (a) and (b). d) replacing the dots with gaussians produces one gaussian with superimposed sine same as in (a), (b), and (c).

Figure 8. FT of two dots with increasing radius. The size of the FT is inversely proportional with the radius of the circle.

Figure 9. FT of two squares with varying width. The thickness of the FT is inversely proportional to the width of the squares.

Figure 10. FT of two gaussian is a gaussian with a super imposed sine. Increase n the variance of the gaussian decreases the size of the FT.
Figure 11 shows the effect of the convolution of a pattern with a dirac delta. This results to an imprint of the pattern at the location of the dirac delta. Figure 11 a) is the convolution of randomly placed dirac deltas with a paw print and a mickey mouse head. Note that the resulting convolution has an increased dimension with the original. The convolution of an NxN matrix with dirac deltas with an nxn pattern results to an N+n-1 by N + n-1 matrix. The placement of the pattern is the relative location of the dirac delta with the center. The convolution in figure 11 a) can be used as an acitivity for finding the hidden mickey. Figure 11 b) is a more challenging convolution since the r, g, and b channels has to be preserved. To do this, I convolved the R, G, and B channels of the colored flower pattern with the randomly placed dirac deltas shown in the left panel. The background of each colored flower pattern was segmented using a threshold. The segmentation however is not perfect especially for the white flower since the background of each colored flower pattern is white. A mask was made so that areas already placed with a flower will not be added with another pattern. Without the mask, the colors of the flowers will be destroyed, since the steps were done separately for each R, G, and B channel. Figure 11 c) increased the dirac deltas and the flower patterns. This method could be used for fast creation of colorful floral patterns.

Figure 11. Convolution of a pattern (right panels) with dirac deltas at random locations (left panels).
Equally spaced dirac deltas produced equally spaced FT. The spacing however is opposite for each FT pair. A widely spaced pattern will have a narrowly spaced FT. This is shown in figure 12.

Figure 12. FT of equally spaced ones. The increase in the spacing of the ones in the pattern produces a decrease in the spacing of the ones in the FT.
Fingerprints: Ridge Enhancement
For a fingerprint, the information are in the ridges of the pattern. The fingerprint however has ink blotches, making the pattern inaccurate. To recover the ridges in the fingerprint, a mask can be used in the FT to preserve the circular peaks corresponding to the ridges. This is shown in figure 13.
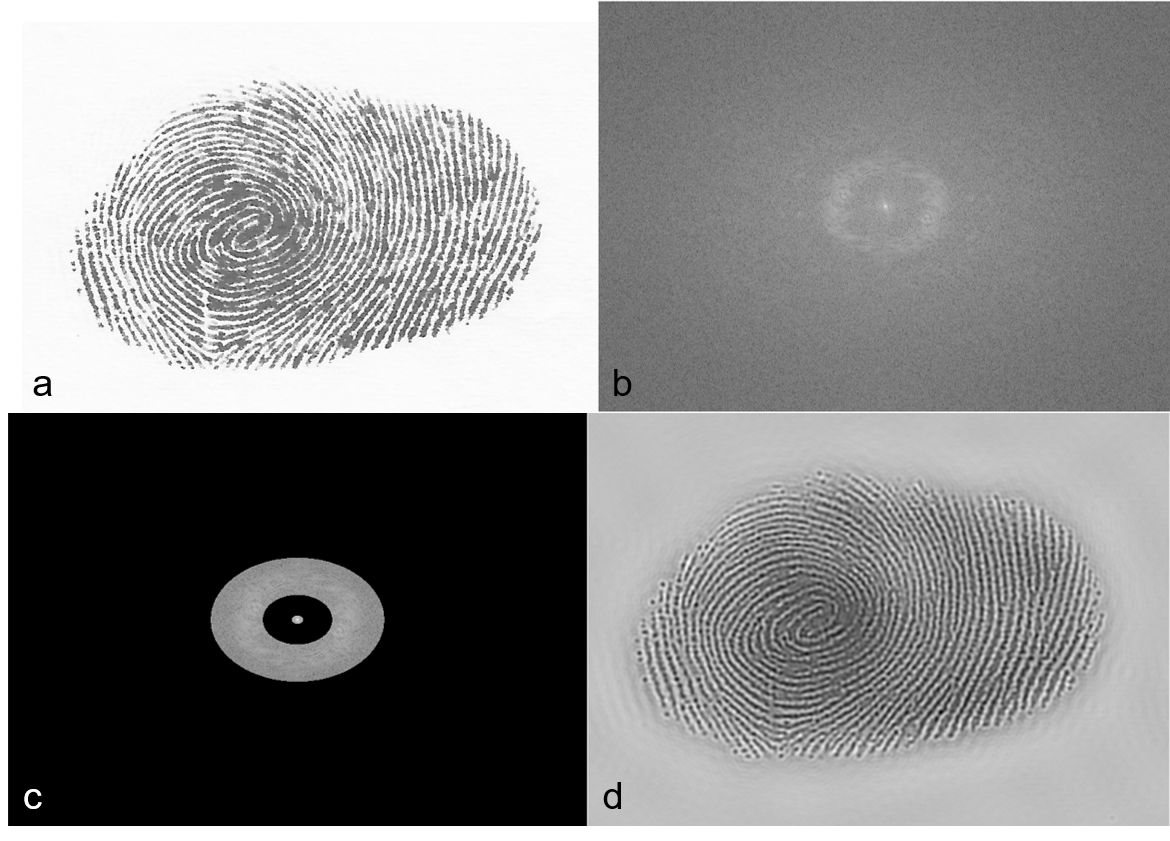
Figure 13. Ridge enhancement of a fingerprint. a) The fingerprint. b) The FT showing a circular ring near the center. c) Isolating the circular ring and the peak at the center using a mask. d) The inverse FT of (c) capturing the ridges of the fingerprint.
Lunar Landing Scanned Pictures: Line removal
Repeating lines can also be removed with the knowledge that the FT of repeating lines are peaks along x or along y. A mask covering the peaks spanning vertically and horizontally in the FT can be used as shown in figure 14. The resulting image from the inverse FT in figure 14 d) shows a cleaned image where the lines were removed. Care should be observed however since some sharp edges which are part of the picture got smoothed out due to some removed signals in the image.

Figure 14. Line removal of a lunar landing image. a) The scanned image. b) The FT showing peaks spanning horizontally and vertically along the center. c) Removing the peaks using a mask. d) The cleaned image.
Canvas Weave Modeling and Removal
For paintings or other materials printed in a canvas, the texture of the canvas messes up with the information contained in the material. From scanned painting, there is a repeating pattern which seems to be not included in the painting. This repeating pattern is similar to the patterns in figure 6. A mask should be created to remove twin peaks of the combined sinusoidal signals. Figure 15 d) shows a clean image. The FT of the peaks removed by the mask, is a weave pattern as shown in figure 15 e).

Figure 15. Removal of canvas weave in a scanned painting. a) The painting. b) the FT of the image. c) Removal of the peaks corresponding to the canvas using a mask. d) The cleaned image. e) The inverse FT of the peaks removed in (b). f) The result of subtracting the cleaned image from the original image.
Mark Twain once said that history doesn't repeat itself, but it does rhyme. - Albert-László Barabási































